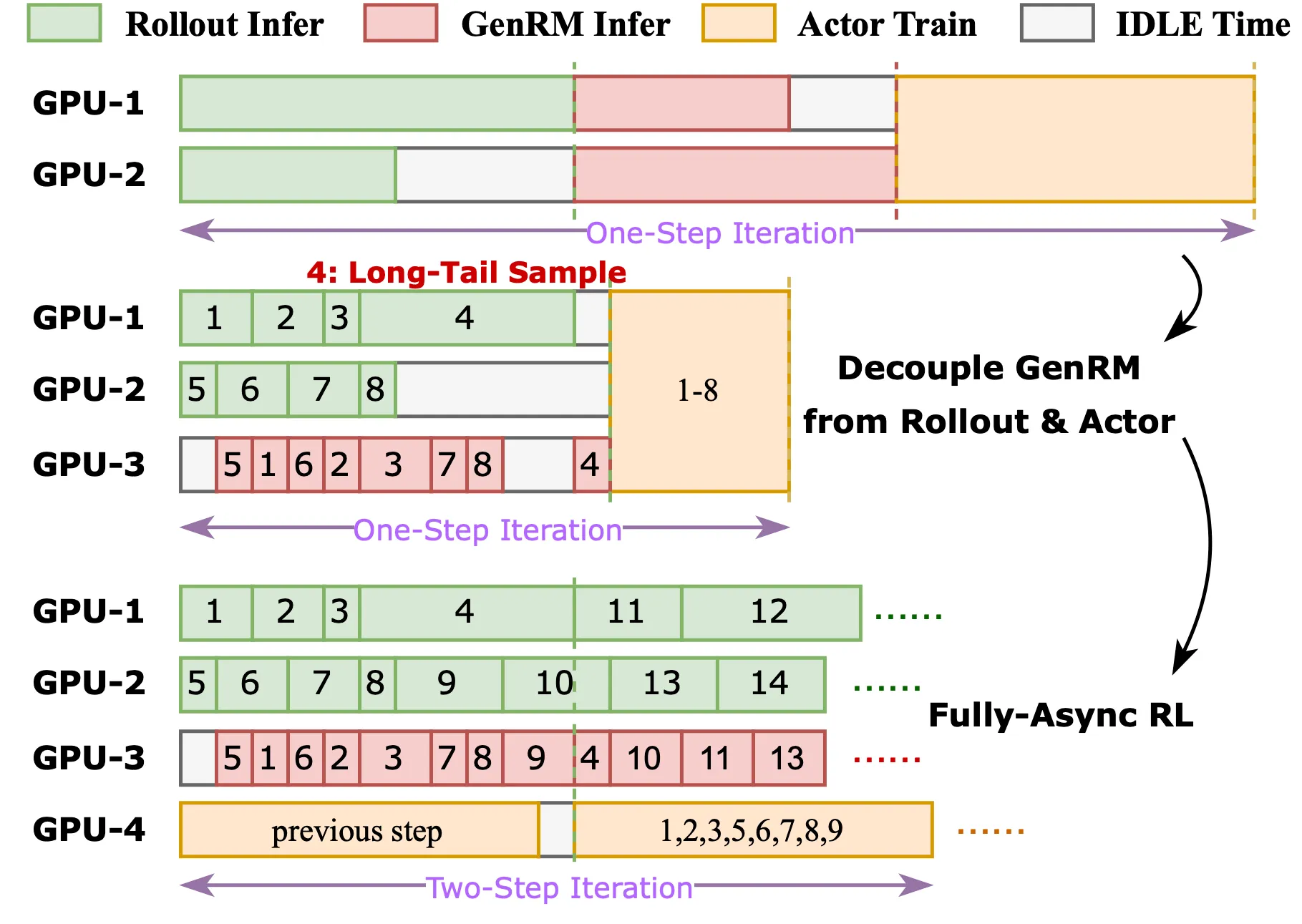
We have also implemented a more flexible and easy-to-use infra design for reward models, which has been added to the veRL repo with details in this doc and will be merged as a key feature in a future release. Welcome to use it!
Let’s start with a recent OpenAI study on LLM hallucinations:
“Language models hallucinate because their training and evaluation processes favor confident guesses over the acknowledgment of uncertainty. Fundamentally, these hallucinations arise as errors in binary classification.”
— OpenAI: Why Language Models Hallucinate
In the context of reinforcement learning, we refer to these “confident guesses” as “flawed positives”, where such flawed guessing rollouts are treated as confident positive signals for policy optimization, thereby reinforcing unreliable reasoning patterns. In this work, we dive into this dilemma, and propose Flawed-Aware Policy Optimization (FAPO), demonstrating the great potential of acknowledging and penalizing these uncertain or flawed patterns to ensure efficient and reliable reasoning.

Flawed Positives are Prevalent in Initial Checkpoints (Figure a): Flawed positives are prevalent across various LLMs (Pre-Trained Model, Instruct Model, and Think Model), which stablish the starting conditions for subsequent RL optimization, accounting for 20%–40% of correct rollouts.
Flawed Positives are Stepping Stones in Learning (Figure b): Flawed positives are most prevalent during the early learning stages but diminish significantly as per-sample confidence improves. This highlights their expected role as natural stepping stones in the learning trajectory, allowing the model to initially reach correct answers before gradually evolving the capability to produce fully correct solutions.
Flawed Positives Persist throughout RL Training (Figure c): As the RL training progresses, flawed-positive ratio remains almost constant at around 30%. This indicates that the optimization process struggles to shift from unreliable reasoning to genuine problem-solving.
Flawed Positives Exert Twofold Effects (Figure d): Assigning negative optimization signals to flawed positives yields substantial performance improvements, although the gains appear more gradually in the early training stages. These findings reveal that flawed positives exert a twofold effect: (1) flawed positives act as stepping stones, enabling the model to achieve rapid capability gains in the early stages, and (2) their improper reward assignment can trap optimization in unreliable reasoning.
Based on GRPO, we also adopt several effective effective strategies such as clip-higher and token-level loss as our standard baseline RL setting.
where denotes a question-answer pair sampled from the data distribution , is the old policy, and controls the clipping range in importance sampling for stability. The advantage is estimated in a group-relative manner:
where is the predicted final answer of old policy and denotes the ground truth.
We first train a generative reward model (GenRM) to detect flawed-positives accurately and comprehensively, with the following RL reward reformulation:
Here, and denote the predicted and ground-truth error indices, and is the total number of steps, ensuring . The process penalty is distance-sensitive: predictions closer to the true error receive higher rewards, while those farther away incur stronger penalties. This design guides the model toward precise error localization and fosters genuine error-detection ability, rather than mere guessing.
With the GenRM detecting flawed positives, we then regulate their roles in the final RL optimization. We introduce a reward-penalization mechanism with a group-relative advantage estimation:
We demonstrate the whole learning process and how FAPO leverage flawed positives. The advantage estimation of FAPO can be formulated in that of GRPO:
where denote the positive rate, negative rate, and flawed positive rate, respectively, and we propose to represent the current learning progress.
The role of flawed positive shift when optimization progress, specifically:
The scaling factor changes over when:
So the optimization direction moves from warm-up to refinement if current learning progress exceeds . Furthermore, when , the advantage estimation is downscaled to stabilize training. In terms of , we adopt a majority-guided strategy, which yields , further determining .
Overall, FAPO provides a principled mechanism for guiding the optimization process, aligning with the ideal learning trajectory where the focus initially lies in producing correct solutions when model capability is limited, and naturally shifts toward refining reliability once correct rollouts surpass incorrect ones.
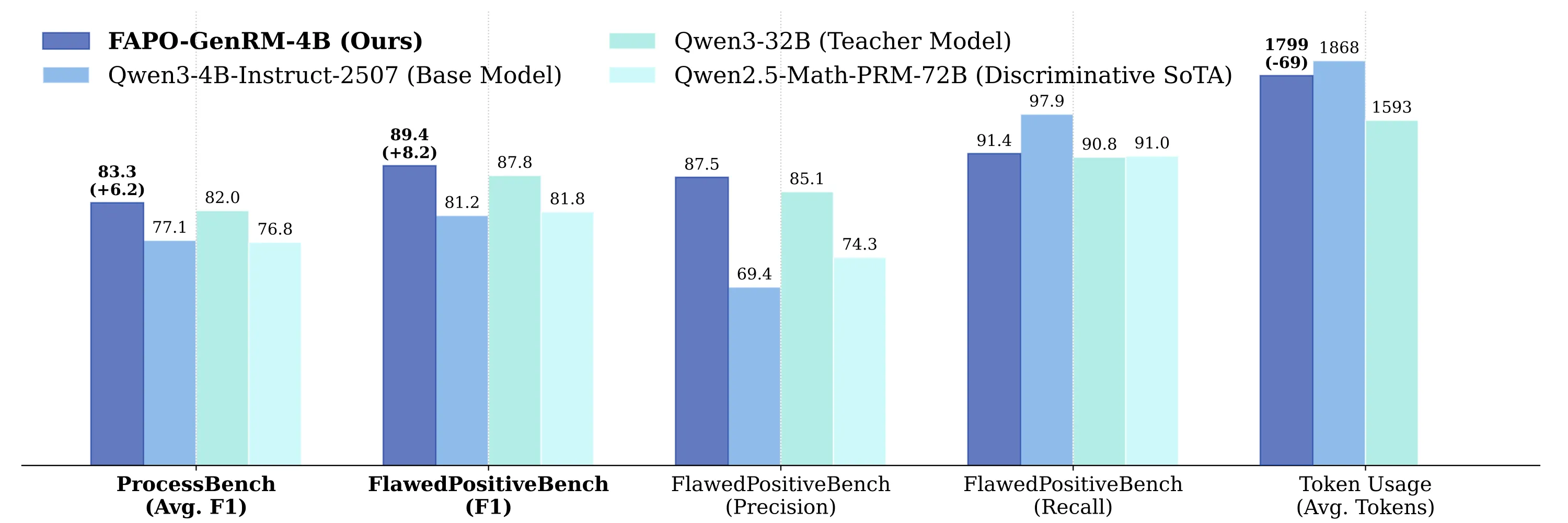
FAPO-GenRM-4B achieves substantial improvements on both FlawedPositiveBench and ProcessBench, even outperforming the teacher model Qwen3-32B, further demonstrating the effectiveness of our approach.
We have also open-sourced the training dataset FAPO-Critic, training scripts, and the final checkpoint.
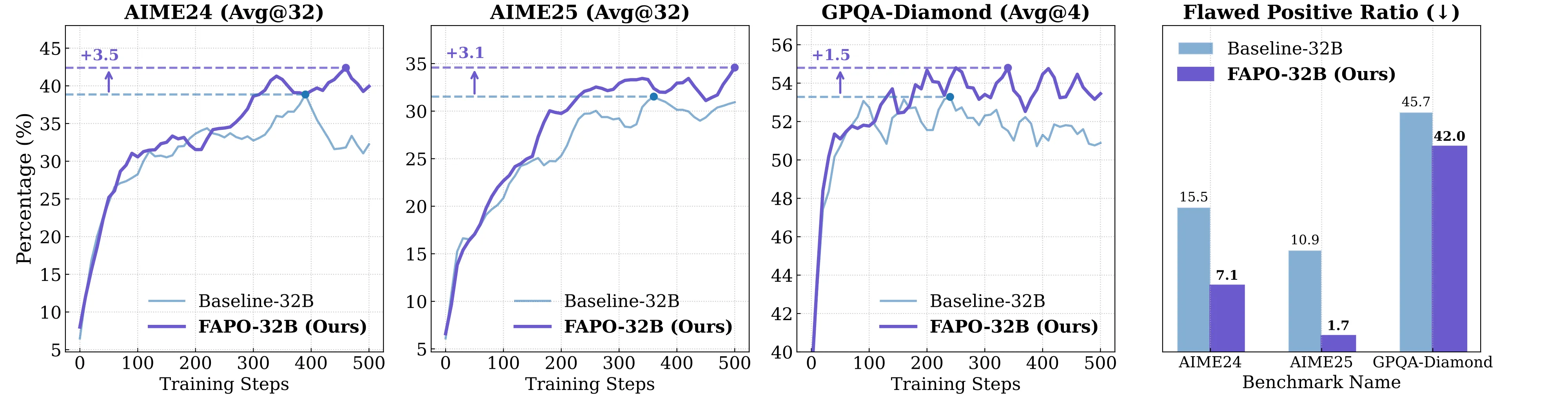
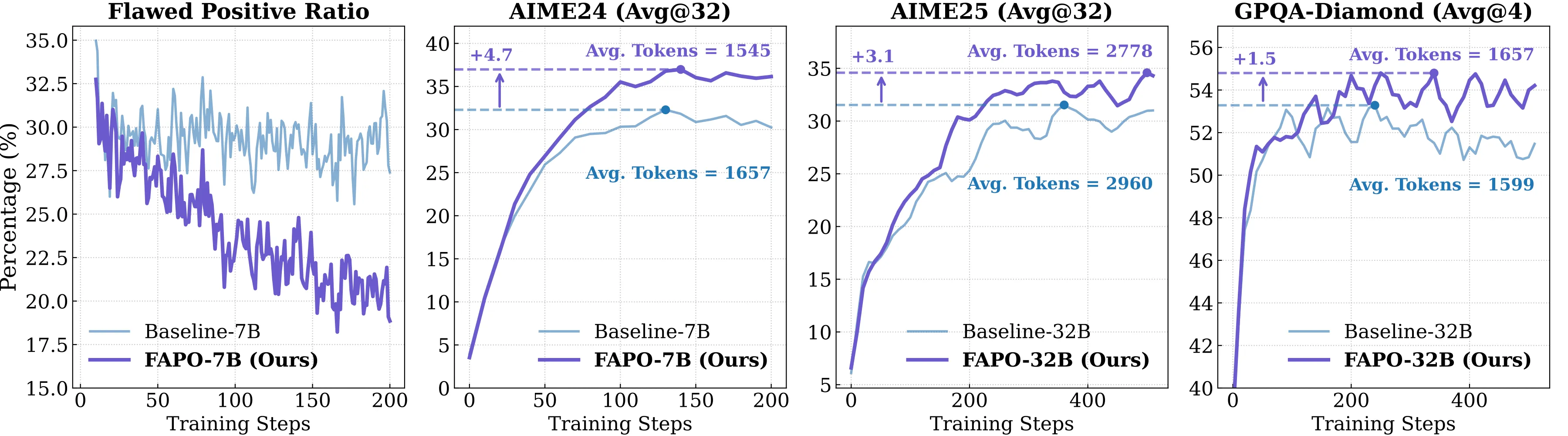
We evaluate FAPO Models in AIME24, AIME25 (Math Domain), and GPQA-Diamond (General Domain), demonstrate the great potential of FAPO in:
(1) Outcome Correctness: FAPO consistently maintains a clear advantage of accuracy over the baselines.
(2) Process Reliability: FAPO responses exhibit a substantially lower flawed-positive ratio.
(3) Training Stability: By mitigating the impact of flawed positives, training stability is enhanced.
We have also open-sourced the training scripts, and the final checkpoint.
Introducing generative reward models (GenRMs) may have a considerable impact on the whole RL process, influencing both algorithmic effectiveness and infrastructure efficiency. Below, we outline the following roadmap (part implemented):
[1/N]: Standalone GenRM seperated from Rollout.
[2/N]: GenRM router to distribute request.
[3/N]: Mixture of colocate and standalone mode.
[4/N]: Fully Async RL Pipeline Construction.
@article{ding2025fapo, title={FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning}, author={Ding, Yuyang and Zhang, Chi and Li, Juntao and Lin, Haibin and Zhang, Min}, journal={arXiv preprint arXiv:2510.22543}, year={2025} }@article{ding2025fapo, title={FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning}, author={Ding, Yuyang and Zhang, Chi and Li, Juntao and Lin, Haibin and Zhang, Min}, journal={arXiv preprint arXiv:2510.22543}, year={2025} }